A fotografia é a técnica de registrar o mundo, que é tridimensional – ou 3D, em uma imagem bidimensional, ou 2D. Sempre que fotografamos, por definição, estamos jogando alguma informação fora. Mas, e se a gente pudesse recuperar pelo menos uma parte dessa informação perdida e recriar objetos em 3D a partir de fotos? É precisamente isso o que a fotogrametria faz.
A fotogrametria é uma técnica que permite extrair informação tridimensional de objetos a partir de duas ou mais fotografias bidimensionais. Em outras palavras, se tivermos mais de uma foto do mesmo objeto, mas em posições diferentes, seremos capazes de identificar alguns pontos em comum e reconstruir alguma informação tridimensional a partir das distâncias relativas desses pontos. Ainda mais, se tivermos fotos o suficiente, seremos capazes até mesmo de reconstruir objetos inteiros.
A fotogrametria, atualmente, vai ainda além. A gente não somente cria um modelo 3D a partir de fotos, como também projeta as imagens originais sobre o modelo, criando texturas que representam o objeto retratado com muita fidelidade. Também é possível extrair medidas com relativa precisão, e a técnica é amplamente utilizada em diversos campos, como na engenharia civil, que escrevi recentemente sobre.
Outras aplicações incluem a produção de objetos para ambientes virtuais, como jogos e guias virtuais de imóveis, cópia com impressora 3D, avaliação de peças mecânicas e mais o que você imaginar. Dominar essa técnica é uma coisa que pode quase te dar super poderes! Dito isso, vamos ao que interessa!
Meshroom
O software que vamos usar nesse tutorial, conforme sugere o título, é o Meshroom. Ele é gratuito e opensource, o que quer dizer que você pode até baixar o código fonte e modificar. Ainda assim, ele é muito fácil de usar se você seguir a receitinha que vou passar aqui.
Requisitos mínimos
Fique atento que a versão mais comum do Meshroom requer uma placa de vídeo da Nvidia, pois ele usa a tecnologia CUDA. Isso não é exclusividade dele, muitos outros software de fotogrametria, inclusive os pagos, exigem uma placa de vídeo dessas. Placas da AMD, como as Radeon ou Vega, não servem porque o CUDA é uma tecnologia própria da Nvidia. Caso você não tenha uma placa dessas, mas mesmo assim queira tentar, existe o MeshroomCL, que é mais lento e mais limitado, mas também funciona bem. Neste tutorial, vou usar a versão que requer a placa da Nvidia. Ele não exige nenhum modelo específico. Qualquer placa fabricada pela Nvidia nos últimos 5 anos deve dar, tanto de desktop quanto de notebook.
Outro requisito de hardware importante é a quantidade de memória RAM. O ideal é ter 16 gb. Com 8 gb talvez não dê pra chegar no fim do modelo. Eu estou usando 12 gb porque o notebook veio com 8 gb e eu tinha mais 4 gb sobrando aqui. Então 12 gb é o requisito mínimo que consigo indicar.
Onde baixar o Meshroom
Para baixar o Meshroom, vá até o site oficial clicando aqui e baixe a última versão. A que estou usando é a 2021.1.0. A instalação é muito simples, basta descompactar o arquivo em qualquer diretório. Eu costumo colocar em C:\Meshroom mesmo. Dentro desse diretório estará o arquivo Meshroom.exe. Basta executar e já vai aparecer a janelinha.
Fotografias para o modelo
Para esse tutorial não ficar longo demais, vou deixar para fazer um de fotografia separado. Por enquanto, vamos focar em como usar o Meshroom. Por isso, estou disponibilizando algumas fotos para a confecção de um modelo de uma coluna de uma ponte com problemas estruturais. Como eu já fiz esse modelo antes, tenho certeza que vai dar certo, e assim você pode aproveitar para testar se tudo está funcionando direitinho antes de tentar fazer o seu próprio modelo do zero.
Para baixar as fotos, basta clicar aqui. Depois, descompacte o arquivo em algum diretório. O Meshroom é meio chato com nomes de arquivos, então evite espaços, acentos, etc. Use diretórios com nomes simples. No meu caso, eu estou usando o E:\fotogrametria\coluna para não ter erro. Já tive modelos que deram errado por causa do nome do arquivo.
Você deve encontrar 71 imagens dentro do arquivo. Elas foram tiradas com o meu drone (mas não em vôo, eu só queria testar a câmera) um DJI Phantom 3 Pro. A câmera tem 12 megapixels, abertura f/2.8 e dist6ancia focal de 20 mm. As fotos foram tiradas a cerca de 1 metro de distância, conforme explicarei no tutorial de fotografia. Não se preocupe com isso agora.
Fazendo amizade com o Meshroom
Quando você executar o Meshroom, verá que ele abre uma janela de terminal e a tela principal. Pode ignorar o terminal e focar só na tela principal mesmo. Nela, encontramos tudo o que precisamos de uma vez só. Veja na imagem abaixo.
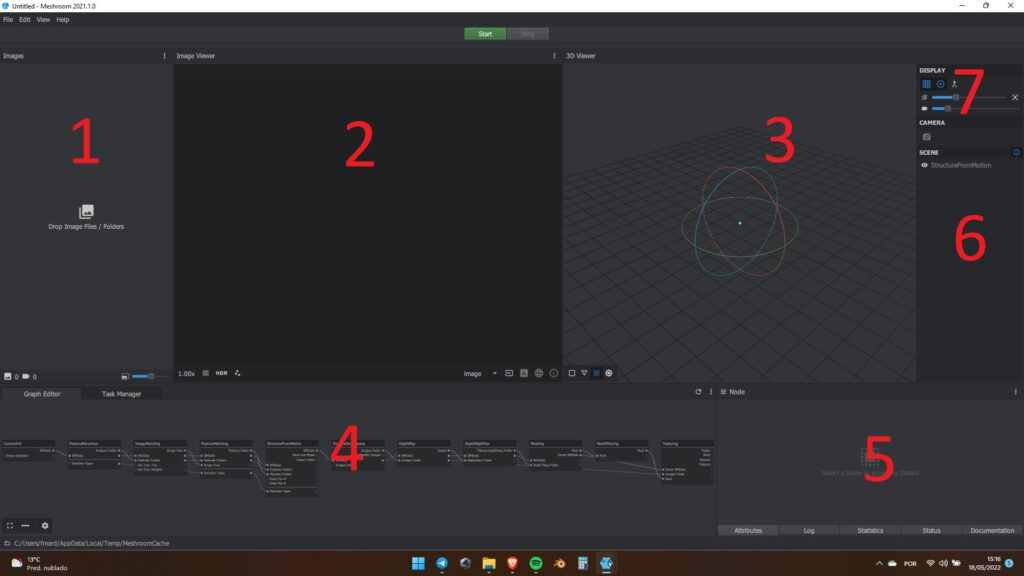
Vamos dar uma olhada, agora, no que cada uma das partes numeradas faz. Vou entrar nos detalhes de cada uma quando for oportuno. Por hora, vamos ver sem muitos detalhes para que serve cada parte.
- Aqui é onde ficam os arquivos com as fotos,
- Nesta área você pode visualizar as coisas 2D. Normalmente, dá pra visualizar as fotos, mas também é possível ver alguns gráficos, feições, etc,
- Aqui é para visualizar as coisas em 3D, como a nuvem de pontos e o mesh,
- Este é o pipeline. Ele é o fluxograma de trabalho do algoritmo,
- Este é o painel que você usará para trabalhar com cada item do pipeline,
- Essa é a lista de coisas que pode ser vista no painel 3,
- Alguns ajustes do painel 3.
Além desses 7 painéis, temos o menu normal do sistema ali em cima (com File, Edit, etc.). Também temos dois botões, o Start e o Stop, que, evidentemente, servem para começar ou parar o processamento. Decore bem os números de cada painel porque eu vou usar bastante daqui pra frente. Essa foto vai ser o mapa para nos orientarmos na interface do Meshroom.
Como carregar as fotos no Meshroom
Para entendermos melhor cada passo, é uma boa idéia carregarmos as fotos do modelo. Para isso, vá até a pasta que você descompactou as imagens, selecione todas, arraste do gerenciador de arquivos do Windows para o painel 1 do Meshroom. Outra opção, que faz exatamente a mesma coisa, é clicar em File no menu lá no topo, e depois em import images. Daí é só escolher os arquivos na telinha que aparecer e clicar em importar. Quando ele terminar, vai ficar assim:
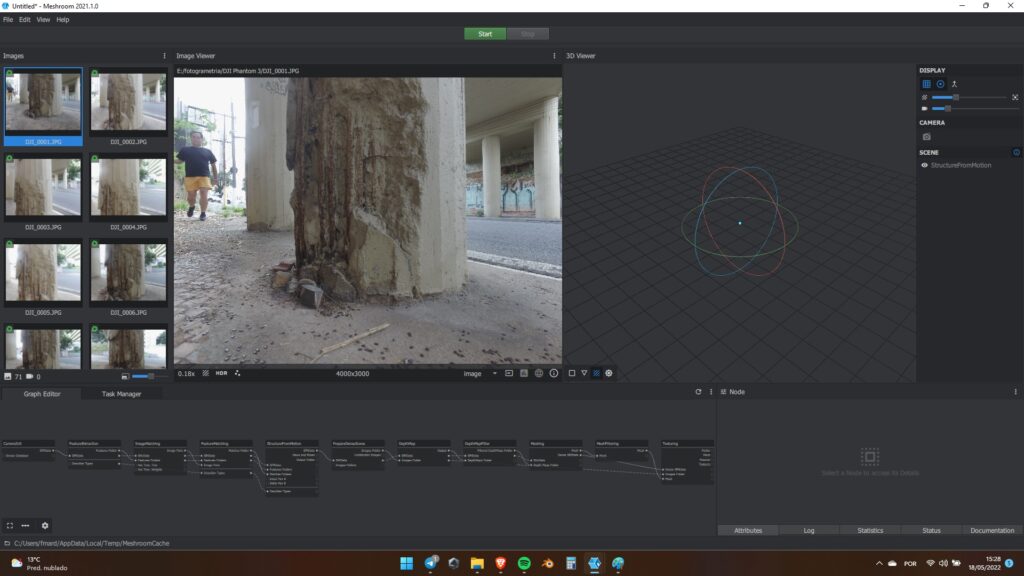
Além do cara aleatório na primeira foto, tem algumas coisas que a gente precisa notar. Além da foto selecionada aparecer no painel ao lado, surgiu um ícone verde em cada uma das fotos, como na imagem abaixo. O que isso quer dizer é que ele identificou, no seu banco de dados, o modelo da câmera utilizada.
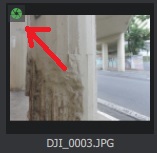
Isso é importante porque uma parte dos parâmetros necessários para montar os modelos são os chamados parâmetros intrínsecos da câmera. Esses parâmetros, em resumo, são as dimensões do sensor e a distância focal da lente. O Meshrrom obtém esses dados automaticamente a partir dos metadados das fotos. Por isso, uma dica importante é usar as fotos direto da câmera. Caso ele não encontre essas informações, ele vai sofrer bem mais pra fazer o modelo.
Se, por acaso, a sua câmera não estiver no banco de dados, ou se a sua lente for manual e a câmera não consiga registrar a distância focal, também vai dar problema. Isso não é tão grave, pois tem como adicionar a câmera específica no banco de dados, mas isso vai ficar para outro tutorial. Porém, o banco de dados contém a maior parte dos celulares, câmeras e drones.
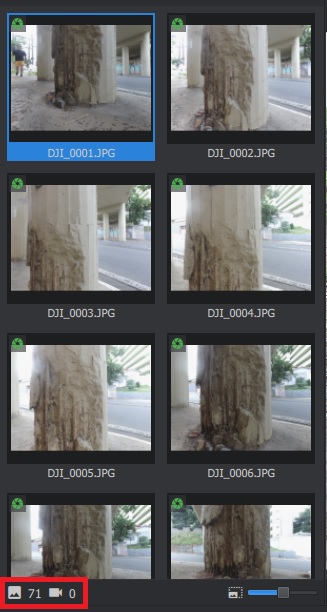
Na parte de baixo do painel de fotos tem dois ícones à esquerda. O mais à esquerda indica o número total de imagens abertas, nesse caso, 71. O mais à direita indica quantas fotos foram usadas no modelo. Por enquanto é 0 porque ainda não tem modelo. Ele vai deixar de ser 0 quando a gente chegar na parte do Structure from Motion.
Como dar zoom e mover as fotos
Em todos os painéis do Meshrrom, inclusive no 2D, no 3D e no pipeline, o zoom é dado com a roda de rolagem do mouse. Role pra frente para ampliar e para trás para diminuir. Para mover, é só clicar com a roda do mouse e arrastar enquanto mantém clicado. Muita gente nem sabe que dá pra clicar com a rodinha do mouse, mas é uma coisa meio comum em aplicações 3D. Se estiver usando só o touchpad do notebook, tenho péssimas notícias. Gaste 10 reais num mouse.
Configurando o algoritmo
Já estamos quase prontos para começar. O Meshroom, por ser um software feito por acadêmicos, é muito completo e possui uma quantidade quase inumerável de parâmetros que dá pra mexer. Porém, ele não é um algoritmo muito estável e a gente pode fazer o modelo divergir mexendo em pouca coisa. Quando o algoritmo diverge, o computador vai ficar horas e horas fazendo contas e não vai chegar a lugar algum. Eu vou dar uns tempos típicos de cada passo, assim você tem uma idéia se está convergindo ou não. Tenha em mente que os resultados variam bastante de acordo a performance do seu computador. Um i3 de terceira geração será muito mais lento que um i7 de décima segunda, por exemplo. O meu é um i5 de 11a geração, então ele é mediano e serve como uma boa base para comparação. Dito isso, vamos por partes.
Como funciona o pipeline
Vamos para o pipeline, que é o painel número 4. A lógica de funcionamento é muito simples. Cada caixinha dessas é um módulo e faz uma função diferente. Cada módulo passa os dados para o seguinte, que faz as suas operações e passa para o próximo e assim por diante, até chegar no último. As informações que vão de um para o outro são representadas pelo fiozinhos que unem as saídas do primeiro com as entradas do segundo. As bolinhas do lado esquerdo são as entradas de dados (inputs) e as do lado direito são as saídas (output). Você pode mover os módulos clicando com botão esquerdo e arrastando, mudar o zoom com a rodinha e mover clicando com a rodinha, igual no painel 2D.
Os módulos podem passar para frente não somente os dados que ele processou, mas também dados de módulos anteriores e configurações. Porém, por enquanto, não precisa se preocupar muito com isso, já vem tudo arrumado de fábrica. Só se você quiser fazer algo mais avançado é que vai ter que mexer nessas coisas. Além do mais, como disse lá em cima, uma das desvantagens do Meshroom é que é muito instável, então é bom não mexer mesmo. De todo modo, precisa saber, pelo menos, pra que serve cada coisa.
Já as partes dos módulos funcionam assim: tem o título e, logo abaixo, os soquetes de entrada e saída de dados. Abaixo disso, quando disponível, tem uma barra cinza e mais soquetes. Esses são as configurações. Alguns deles têm uma setinha apontando pra baixo no final. Se você clicar vai abrir as configurações avançadas.
Quando você clica num módulo, as informações correspondentes vão aparecer lá no painel número 5. Note que, na parte de baixo dele, tem 4 abas: attributes, log, statistics, status e documentation. Os nomes são auto-explicativos e representam exatamente o que você vai encontrar em cada um deles. Por enquanto, o que interessa são o attributes e o documentation.
Vamos dar uma olhada, agora, no que faz cada caixinha.
Camera Init
O melhor amigo de todo usuário de software livre é a documentação, então vou traduzir o que diz essa aba para cada um dos módulos.
Este módulo descreve o seu conjunto de dados. Ele lista os candidatos a poses, adivinha o tipo de óptica, o comprimento focal inicial e quais imagens compartilham os mesmos parâmetros iniciais de câmera, bem como possíveis montagens de câmeras.
Quando você importa novas imagens no Meshroom, este módulo é configurado automaticamente a partir da análise dos metadados da imagem. O software pode suportar imagens sem quaisquer metadados mas é recomendado que os tenha por robustez.
Metadados
Os metadados permitem que as imagens sejam agrupadas e provêem uma inicialização da distância focal (em unidades de pixel). Os metadados são necessários para:
– comprimento focal: o comprimento focal em milímetros
– fabricante e modelo: essa informação permite converter o comprimento focal de milímetros para pixels usando um banco de dados de sensores
– número de série: permite identificar um único ou múltiplos dispositivos com o mesmo fabricante ou modelo e otimizar seus parâmetros separadamente (no caso da fotogrametria)
Em outras palavras, o Camera Init vai dizer ao Meshroom que câmera você usou, a lente que usou e se usou a mesma câmera ou câmeras diferentes em cada pose. Uma definição importante é a seguinte:
POSE: é a combinação de rotação e posição de uma câmera na cena
Deste modo, cada foto importada é uma pose diferente, e o Meshroom trata cada pose como uma câmera diferente quando importa os dados. É o Câmera Init que diz se é a mesma câmera ou não.
Agora, podemos salvar o projeto. Vá em file e save as. Eu costumo salvar o arquivo na mesma pasta onde estão as fotos. Os arquivos que o Meshroom gerar daqui pr frente ficarão nessa pasta que você salvar o projeto. Vale os mesmos cuidados de sempre, como evitar espaços e pontuações no nome do diretório. Aí é só clicar com o botão direito do mouse sobre o módulo Camera Init e clicar em Compute. Este módulo costuma ser executado em 1 segundo ou menos, é o mais rápido. Você vai ver uma barra verde surgir sob o titulo do módulo, para indicar que foi computado.
Feature Extraction
Este módulo é uma das partes mais importantes do Meshroom, porque ele identifica pontos que podem ser rastreados nas fotos. Com essa informação é que ele vai montar o quebra-cabeças 3D nos passos seguintes. Portanto, o sucesso do modelo depende muito desse módulo. Segue a documentação:
Este módulo extrai grupos de pixels identificáveis que são, em algum grau, invariáveis a mudanças de pose da câmera durante a aquisição das imagens. Portanto, uma feição da cena deveria ser ter descrições de feição similares em todas as imagens.
Este módulo implementa os seguintes métodos:
– SIFT: O método mais padrão. Ele é o original e recomendado para a maioria dos casos.
– AKAZE: pode ser uma solução interessante para extrair feições em condições mais desafiadoras. Ele pode pegar ângulos maiores que o SIFT, mas tem desvantagens. Ele pode extrair muitas feições, mas a repartição nem sempre é boa. É sabido que é bom em superficies difíceis como a pele.
– CCTAG: é um tipo de marcador com três ou quatro coroas. Você pode pôr marcadores na cena durante a sessão de fotos para reorientar automaticamente e e re-escalar a cena para uma tamanho conhecido. Ele é insensível ao desfoque por movimento, profundidade de campo, ou obstrução. Tome cuidado para ter uma margem branca grande o suficiente em torno dos seus CCTags.
Aqui tem algumas coisas que a gente precisa tratar, e que vão te ajudar na hora de fotografar os objetos para os seus modelos. A definição mais importante é o de feição (na documentação é usada a palavra feature). Pense um pouco em como você reconhece uma pessoa pelo rosto. Ela possui uma série de características próprias que, em conjunto, formam uma identidade visual. Você identifica a mesma pessoa por diversos ângulos diferentes porque sempre tem algum conjunto de feições que são reconhecíveis e que não mudam tanto com o ângulo. O que o Meshroom está tentando fazer aqui é exatamente isso.
Os algoritmos que ele usa para reconhecer essas feições são o SIFT, o AKAZE, o DSPSIFT e o CCTAG. Como ele diz ali, o mais comum é o SIFT, e geralmente é o que dá bons resultados com tempo de computação razoável. O AKAZE, na minha experiência, nunca funcionou, então não recomendo usar ele. O DSPSIFT, que não está na documentação, é quase sempre melhor que o SIFT, mas leva entre 5 e 10 vezes mais tempo para executar. Já o CCTAG nunca usei, mas merecia umas tentativas.
Na dúvida, use o SIFT mesmo. Há, ainda, mais algumas opções, como o SIFT FLOAT, mas vamos ignorá-lo por enquanto. Os únicos parâmetros que recomendo que você mexa nessa etapa são Describer Density e Describer Quality. Eles indicam a quantidade e a qualidade dos descritores das feições. Porém, aumentar esses parâmetros para high ou ultra nem sempre melhoram o modelo. Já me ocorreram casos de ter que diminuir para low para o Meshroom encontrar todos os pontos corretamente. Também tenha em mente que aumentá-los para high ou ultra pode prolongar o tempo de processamento em várias vezes. Na primeira vez, deixe tudo em normal mesmo e veja no que dá.
Uma opção que você pode mudar é o Force CPU extraction. Se desabilitá-la, ele vai tentar usar a GPU para caçar as feições, o que costuma ser bem mais rápido. Porém, se a memória da GPU não for suficiente, ele vai dar erro. Se as suas imagens forem grandes, tipo uns 24 megapixels, vai precisar de mais memória de vídeo, tipo uns 8 gb. Na dúvida, deixe a CPU fazer o serviço.
Para este tutorial, vamos continuar sem mudar nada. Clique com o direito no módulo e, em seguida, compute. O Meshroom vai procurar feições e criar descritores em todas as imagens. Repare que a barrinha sob o título ficou laranja e azul. Ele dividiu a tarefa em várias, duas nesse caso. A que está sendo executada no momento fica laranja, as que estão na fila ficam azuis. Conforme for executando as etapas, elas vão ficando verdes. Você pode acompanhar o processamento clicando em log, no painel 5.
Quando ele terminar essa etapa, você poderá visualizar as feições no painel 2. Para isso, basta selecionar a foto que você quer ver no painel 1 e clicar no ícone que tem três pontinhos no canto inferior esquerdo do painel 2. Veja como fica na imagem abaixo. Isso é importante porque pode mostrar áreas no seu modelo que são problemáticas. Aí você pode mudar para descritores diferentes e tentar de novo. No caso, ficou ótimo, é só seguir.
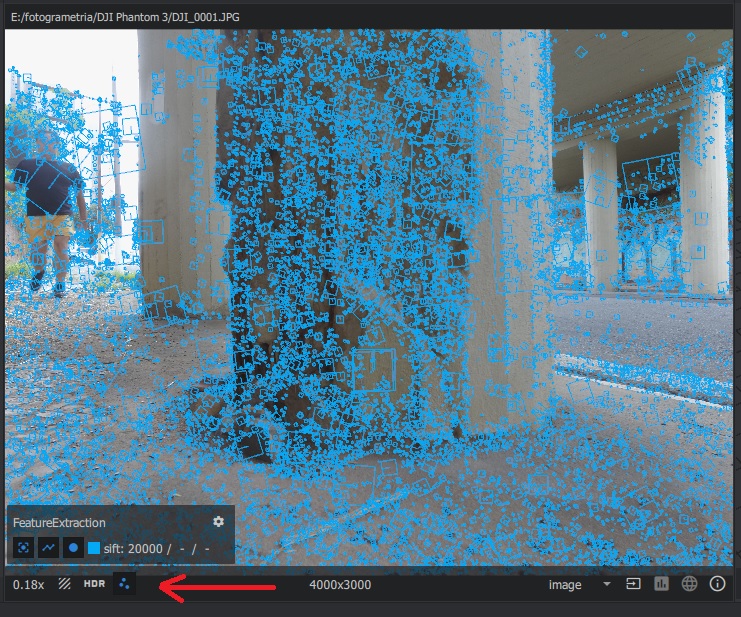
Essa parte deve levar uns 15 minutos.
Image Matching
Agora que o Meshroom tem uma lista de feições com as suas respectivas descrições, ele precisa encontrar correspondências entre as imagens para formar pares entre elas. Vamos ver o que diz a documentação:
A meta desde módulo é selecionar correspondências entre pares de imagens. A ambição é encontrar imagens que estejam olhando para as mesmas áreas da cena. Graças a este módulo, o Feature Matching terá que computar apenas os pares de imagens selecionados.
Ele provê diversos métodos:
– VocabularyTree: Usa técnicas de recuperação de imagens para encontrar as que compartilham o mesmo conteúdo sem o custo de resolver todas as combinações de feições em detalhes. Cada imagem é representada numa descrição concisa que permite computar as distâncias entre todos os descritores de imagens de maneira muito eficiente. Se a sua cena contém menos que “Voc Tree: Minimal Number of Images”, todos os pares de imagens serão selecionados.
– Sequential: Se a sua entrada é uma seqüüência de vídeo, você pode usar esta opção para ligá-las no tempo.
– SequentialAndVocabularyTree: Combina o método sequencial com Voc Tree para habilitar as conexões entre quadros-chave em diferentes tempos.
– Exhaustive: exporta todos os pares de imagens.
– Frustum: Se todas as imagens são poses conhecidas, computa a interseção entre as câmeras parar criar a lista de pares de imagens.
– FrustumOrVocabularyTree: Se as imagens possuem poses conhecidas, use o Frustum ou o VocabularyTree.
Tem um monte de coisas aqui que, por enquanto, a gente não precisa saber. O que é bom entender é o tal do Vocabulary Tree que, na verdade, é bem simples. Imagine que você está vendo várias fotos e que, em algumas, tem um gato preto. Então você marca nelas “gato preto”. Agora, você pega todas as fotos e coloca numa pilha das que contêm “gato preto”. Na próxima etapa etapa, você vai procurar por feições somente entre pares das fotos que estejam em “gato preto”. Ou seja, tudo o que não tem gato preto você não precisa olhar. É claro que o Meshrrom faz isso em linguagem de computador, ele atribui um vetor com números a cada imagem, mas a lógica é exatamente a mesma.
As outras opções referem-se a métodos com vídeo ou estúdios de fotogrametria, que não são o caso aqui, então vou ignorá-las. Mande computar e vamos para o próximo passo.
Esse módulo deve ser computado em menos de 1 segundo.
Feature Matching
Agora que temos as imagens separadas em pilhas por vocabulário, vamos dar uma olhada em todas as feições que cada uma tem e fazer uma lista de correspondências bem detalhadas. A documentação diz o seguinte:
Este módulo encontra as correspondências de todas as feições entre os candidatos a pares de imagens.
Ele é executado em dois passos:
1- Correspond6encias fotométricas
Ele executa as correspond6encias fotométricas entre os grupos de descritores de feições das duas imagens da entrada. Para cada descritor de feição da primeira imagem, ele procura pela correspondência mais próxima na segunda e usa um valor de gatilho relativo entre elas. Essa suposição mata feições em estruturas repetitivas, mas tem se mostrado ser um critério muito robusto.
2- Filtragem geométrica
Faz uma filtragem geométrica dos candidatos a correspondência fotométrica. Ele usa as posições das feições das imagens para fazer o filtro geométrico usando geometria epipolar em algoritmo de detecção de pontos espúrios chamado RANSAC (RANdom SAmple Consensus). Ele seleciona aleatoriamente um pequeno grupo de correspondências de feições e computa a matriz fundamental (ou essencial), então verifica o número de feições que valida o modelo e faz iterações dentro da lógica do RANSAC.
Ok, agora a coisa ficou técnica. O que ele está dizendo, em linguagem de gente normal, é o seguinte. O módulo é executado em duas etapas: na primeira, ele procura por imagens de feições que sejam parecidas e no segundo verifica se faz sentido geometricamente. O primeiro passo funciona pegando pequenas amostras das imagens originais em torno das feições e em seguida compara com as imagens candidatas em outra foto. Nesse caso, como é uma comparação fotométrica, a referência é a intensidade luminosa dos pixels. É fácil entender isso. Numa foto, cada pixel tem um valor de intensidade que vai do preto até o branco. Cada imagem é um conjunto de pixels e cada pixel tem a sua intensidade. Portanto, coisas parecidas terão intensidades parecidas em cada pixel.
Uma analogia seria a seguinte. Imagine um painel com cartas de baralho e que você tenha tirado duas fotos em ângulos diferentes. Queremos identificar, por exemplo, a posição da rainha de copas nas duas fotos. Para isso, primeiro criamos um vocabulário, ou seja, palavras que descrevem as cartas. Por exemplo, meu vocabulário será o naipe. Então, coloco um rótulo em cada uma das cartas do painel, que são as feições, com o naipe. Em seguida, posso descartar tudo o que não for copas, porque quero a rainha de copas.
Agora, posso fazer o mesmo e colocar um rótulo para figuras e outro para números. Daí posso descartar tudo o que for número. Assim, fico com apenas quatro cartas de copas: ás, valete, rainha e rei. Por fim, saio comparando pixel por pixel da carta que estou à procura com as quatro que sobraram em cada foto e identifico a rainha de copas. Agora eu sei, em cada foto, onde estão as rainhas de copas e as suas posições.
O passo seguinte é determinar se as posições entre as fotos fazem sentido. Para isso eu comparo as posições das rainhas de copas nas duas fotos e computo as distâncias. Porém, nesse passo, é preciso de mais referências, então vamos dizer que eu também saiba a posição do três de paus nas duas fotos. Deste modo, eu sei a distância entre o três de paus e a rainha de copas na primeira e na segunda fotos. Agora, posso comparar essas distâncias e ver se faz sentido. Imagina fazer o mesmo com todas as cartas.
Eu poderia fazer uma ilustração visual disso mas, além da preguiça, quero que você faça um esforço de entender isso sem ajuda visual. Isso vai te ensinar bem claramente como a coisa toda funciona.O Meshroom faz esse processo para todos os pontinhos azuis de todos os pares de fotos que ele encontrou até agora. Note que, se não fosse o vocabulário, ele teria que sair comparando pequenas imagens em todas as fotos, o que é uma tarefa computacionalmente muito mais pesada. Esses passos servem para simplificar o processo, torná-lo mais preciso e rápido o suficiente para poder ser computado em tempos plausíveis.
Essa etapa leva uns 10 minutos.
Structure From Motion
Essa é a parte mais crítica do processo todo, e é onde o modelo 3D, de fato, começará a ser montado. Vejamos a documentação:
Este módulo analisará as correspondências entre feições para entender as relações geométricas por trás de todas as observações 2D e inferir a estrutura rígida de cena (pontos 3D) com a pose (posição e orientação) e a calibração interna de todas as câmeras. O pipeline é um processo de reconstrução crescente (chamado SfM incremental): primeiro ele computa uma reconstrução inicial a partir de duas vistas que é iterativamente estendida pela adição de novas vistas.
1- Fundir duas vistas correspondentes em pistas
Ele funde todas as feições correspondentes entre os pares de imagens em pistas. Cada pista representa um candidato a ponto no espaço, visível a partir de múltiplas câmeras. Entretanto, a essa altura, ele deve conter muitos pontos espúrios.
2- Par inicial
Ele escolhe o melhor par inicial de imagens. Essa escolha é crítica para a qualidade da reconstrução final. Ele deve prover, de fato, correspondências robustas e conter informação geométrica confiável. Portanto, esse par de imagens deve maximizar o número de correspondências e a repartição das feições correspondentes em cada imagem. Ao mesmo tempo, o ângulo entre as câmeras deve ser grande o suficiente para prover informação geométrica confiável.
3- Geometria inicial do par de vistas
Computa a matriz fundamental entre as duas imagens selecionadas e considera que a primeira seja a origem do sistema de coordenadas.
4- Triangulação
Agora, com a pose das duas primeiras câmeras, ele triangula as feições 2D correspondentes em pontos 3D.
5 – Seleção da melhor vista
Depois disso, ele seleciona todas as imagens que tenha encontrado associações suficientes e que já tenham sido reconstruídas em 3D.
6 – Estimativa de novas câmeras
Baseado nessas associações entre 2D e 3D, ele realiza a ressecção de cada uma dessas câmeras novas. A ressecção é um algoritmo de Ponto-e-Perspectiva (PnP) em um modelo RANSAC para encontrar a pose da câmera que valida a maioria das associações de feições. Para cada câmera, uma minimização não-linear é feita para refinar cada pose.
7 – Triangulação
Dessas novas poses de câmeras, algumas pistas tornam-se visíveis por duas ou mais câmeras resseccionadas e faz a triangulação entre elas.
8 – Otimização
Faz o ajuste de grupo (Bundle Adjustment) para refinar tudo: parâmetros extrínsecos e intrínsecos de todas as câmeras bem como as posições de todos os pontos 3D. Ele filtra os resultados do Bundle Adjustment removendo todas as observações que possuem alto erro de reprojeção ou ângulos insuficientes entre as observações.
9 – Repetir 5 a 9
Agora que temos novos pontos triangulados, conseguimos mais imagens candidatas para as próximas melhores vistas e podemos iterar de 5 até 9. Ele faz as iterações dessa maneira, adicionando câmeras e triangulando as feições 2D em pontos 3D e removendo pontos 3D que foram invalidados, até que novas vistas não possam mais ser encontradas.
Agora a coisa ficou feia, né? De fato, complicou. Mas vamos tentar entender o que está acontecendo. Dentre aqueles pares de imagens que foram obtidas nos passos anteriores, ele vai escolher um inicial que tenha a maior correspondência possível, com o objetivo de aumentar a chance de sucesso. Agora, ele cria uma vista baseada nessas duas imagens, com posições aproximadas das feições no espaço. Com um algoritmo de triangulação, ele estima as posições das câmeras no espaço.
Em seguida, ele seleciona a melhor vista que encontrou e parte para uma nova imagem, a qual triangula e adiciona às vistas que já possui. Os pontos obtidos são otimizados através de um algoritmo que faz o ajuste em grupo de todos os parâmetros. Ele repete o procedimento para todas as fotos até que encontre um modelo total que não permita mais otimizações. O resultado desse processo é a chamada nuvem de pontos, e o nome é auto-explicativo.
Sem mexer em nada, mande o Meshroom computar esse módulo. Ele deve levar uns 4 minutos e o resultado será como esse da imagem a seguir. Note duas coisas: apareceram pontos vermelhos na imagem do painel 2 e uma nuvem de pontos no painel 3, que é o visualizador 3D. Os pontos vermelhos são as feições que foram usadas par criar o modelo 3D, e a nuvem de pontos é a versão rudimentar do modelo.
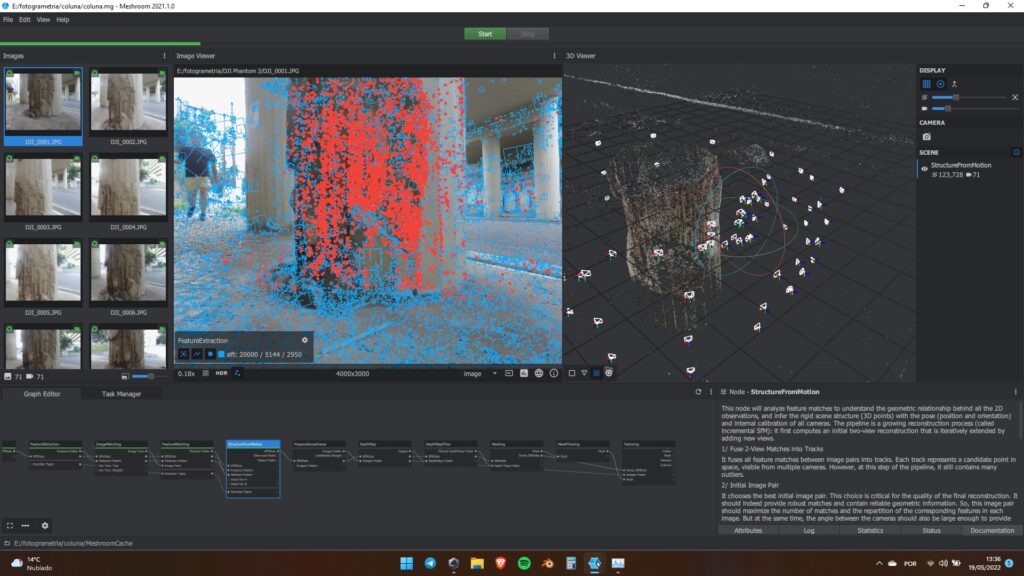
Também acontece uma terceira coisa. Ali no painel onde tem as miniaturas das fotos, no seu canto inferior esquerdo, o ícone das câmeras agora mostra o número 71. Isso quer dizer que 71 imagens foram empregadas para gerar o modelo. Como partimos de 71 imagens ao todo, tivemos um aproveitamento de 100%. Esse é um bom indicador para saber se o modelo está indo bem. Quando muitas imagens não são levadas em conta é porque elas não foram tiradas adequadamente ou você está usando imagens demais ou escolheu uma quantidade de feições muito grande no Features Extraction. Como resolver esse problema é assunto para um outro artigo. Hoje o objetivo é te ensinar a chegar no final de um modelo.
Já o painel 3D te permite ter uma idéia do que está saindo do modelo. Aqui já dá pra saber se tem chance de dar certo ou não. Para manipular o modelo, você pode clicar com o botão esquerdo e arrastar para girá-lo ou pressionar shift enquanto clica com o esquerdo e arrasta para movê-lo. A roda de rolagem serve para controlar o zoom, e se você clicar com ela, segurar e arrastar, ele move o modelo, exatamente como funciona com shift + botão esquerdo. Dê uma boa olhada no modelo e veja se ele faz sentido, ou seja, se está formando o objeto que deveria ter sido formado.
Outra coisa importante é que ele mostra as posições da câmera. Cada foto deve virar uma vista, e elas são indicadas pelos desenhos em forma de pirâmide com topo cortado (ok, eu não sei o nome desse tipo de sólido). O retânglo maior indica a frente da câmera e o menor a posição do sensor, assim o eixo óptico da câmera passa pelo centro dos dois. Com essa simbologia dá pra saber exatamente em qual direção a câmera estava apontando. Se foi você quem tirou as fotos, pode ter uma idéia melhor se as posições estão corretas.
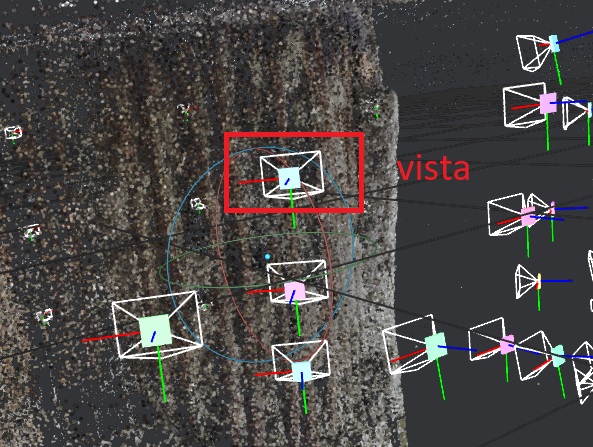
Um outro indicador de que o modelo vai bem é que não tem nenhuma câmera em posição bizarra. Às vezes isso acontece e é preciso revisar as configurações e as fotos. Existem algumas coisas que podem ser feitas mas, como já disse, vou deixar o debug pra outra ocasião. No entanto, você sempre tem que ir olhando passo-a-passo e conferindo se o resultado faz sentido. Nunca trate o Meshroom como uma caixa preta.
Prepare Dense Scene
Agora que temos a primeira aproximação do modelo 3D, queremos criar uma representação com muito mais pontos para que o modelo fique bem completo. Os próximos três módulos farão exatamente isso. Sobre o Prepare Dense Scene, a documentação somente diz:
Este módulo apenas exporta imagens não-distorcidas para que o mapa de profundidade e a texturização possa ser computadas em imagens de pinhole sem distorções.
O termo principal aqui é o pinhole (do inglês pin + hole, ou furo de alfinete). Uma câmera pinhole é o modelo mais rudimentar de câmera e ela é constituída por uma superfície com um furo muito pequeno (pinhole) e uma tela onde a imagem é projetada. Esse tipo de câmera não possui distorções de lente. O que este módulo está fazendo é justamente tentando criar imagens que correspondam a uma câmera ideal, que seria a pinhole.
É só executar. Esse módula leva uns 2 minutos.
Depth Map
Agora, ele vai pegar cada câmera e estimar a profundidade de cada pixel da imagem. Vejamos a documentação:
Para cada câmera que foi estimada pelo Structure from Motion, ele estima o valor da profundidade por pixel.
Ajuste o valor de escalonamento (downscale) para computar os mapas de profundidade a uma resolução maior ou menor. Use o fator de escalonamento como 1 (máxima resolução) apenas se a qualidade das imagens for realmente alta (câmera num tripé com óptica de alta qualidade)
Ou seja, este é um passo que influencia bastante o resultado final. Outro problema de aumentar a resolução é que o consumo de memória aumenta exponencialmente, então tem que tomar um pouco de cuidado aqui. Sempre usei o Downscale como 2 e os resultados sempre foram bons. Não vamos mexer em nada por aqui. Apenas execute o módulo, ele deve demorar uns 20 minutos.
Depth Map Filter
Neste módulo, o resultado do Depth Map é filtrado para remover pontos espúrios. De acordo com a documentação:
Filtra os valores do mapa de profundidade que não são coerentes em múltiplos mapas de profundidade. Isso permite filtrar pontos instáveis antes de começar a fusão de todos os mapas no módulo Meshing.
Agora é só executar, vai levar uns 3 minutos.
Meshing
Essa é uma das etapas mais importantes e é onde a nuvem de pontos e os mapas de profundidade serão usados para gerar uma rede, criando o modelo 3D de fato. Segue a documentação:
Este módulo cria uma representação da superfície geométrica densa da cena.
Primeiro, ele funde todos os mapas de profundidade numa nuvem densa global com resolução adaptativa. Então cria tetraedros com um algoritmo do tipo 3D Delaunay e um procedimento é feito para computar os pesos nas células e os pesos nas facetas que conectam as células. Um método gráfico é aplicado para cortar otimamente o volume. Esse corte representa a rede da superfície.
É… esse foi difícil de traduzir e muito pior pra interpretar. Mas o que ele está dizendo que vai juntar tudo para ligar os pontos da nuvem usando os dados dos mapas de profundidade. Nessa parte, existem duas coisas para se ficar atento. A primeira é que o número total de pontos vai afetar o uso de memória no último passo, que é a texturização. Por isso, eu sempre coloco Max Input Points como 20.000.000 e Max Points como 2.000.000. Com isso, sempre cabe nos meus 12 gb de RAM. Se você tiver mais memória pode usar mais, se tiver menos, pode usar menos. Lembrando que aumentar o número de pontos também pode aumentar desproporcionalmente o tempo de processamento.
A segunda coisa é que o Meshroom modela o ambiente inteiro. Se você olhar na janela 3D, vai ver que pega até coisas do outro lado da rua e do muro que tem atrás da coluna. Entretanto, neste modelo, queremos somente a coluna. A gente até pode criar o modelo todo, mas os 2.000.000 de pontos que temos disponíveis seriam distribuídos em coisas que não temos interesse. O melhor seria que eles ficassem onde queremos extrair o máximo de informação.
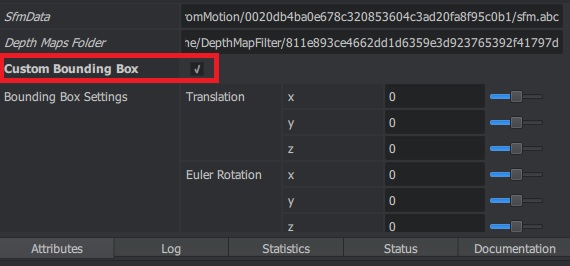
Porém, o Meshroom tem uma solução pra esse problema. Na aba Attributes do Meshing, procure pela caixinha Custom Bounding Box e clique nela, veja imagem abaixo.
Agora, dê um clique duplo no módulo Meshing lá no Pipeline. Você vai ver a caixinha aparecendo no modelo 3D. Agora, temos que colocar a coluna dentro da caixinha. Para isso, podemos usar as setinhas na tela 3D. Espero que a descrição que eu dê agora seja suficiente, porque é meio difícil descrever o procedimento por escrito, mas eu tenho certeza que você vai pegar o jeito bem rápido. A caixinha tem um gizmo no centro, que é composto por três círculos e três eixos, um vermelho, um verde e um azul. Se você clicar nos círculos e arrastar, vai girar a caixa em torno daquele eixo.
Já os eixos têm um pontinha quadrada e uma setinha mais pra frente. Na pontinha quadrada você acerta o tamanho naquele eixo, e coma setinha você desloca sobre aquele eixo. Tenta um pouco ali que você vai perceber. Espero que a imagem abaixo ajude. Aí é só fazer a coluna caber dentro da caixinha.
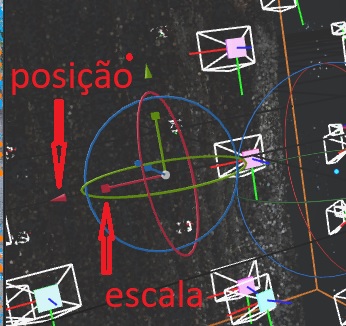
Uma coisa que pode te ajudar é que ali no painel 7 tem um ajuste para o tamanho dos pontos da nuvem e para o tamanho das câmeras. Nesse ponto eu sempre coloco as câmera em zero porque elas só atrapalham, e aumento ou diminuo os pontos para melhorar a visualização. Minha caixinha ficou assim:

Agora pode rodar o Meshing, deve levar uns 5 minutos. Quando acabar, dê um clique duplo no módulo do Meshing que ele vai abrir o modelo no visualizador 3D. Deve aparecer algo como na figura abaixo. Você pode clicar onde marquei com a setinha para ligar ou desligar a visualização da nuvem de pontos ou do modelo 3D.
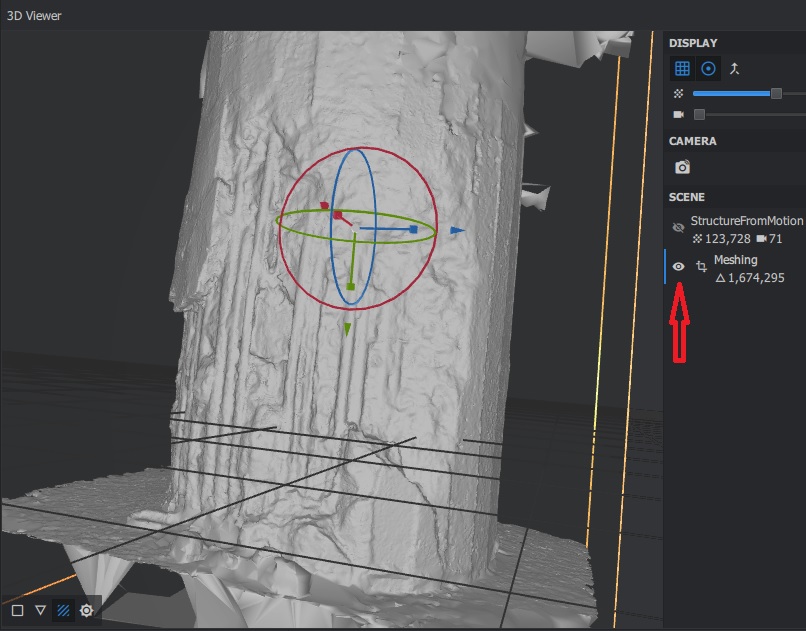
O nosso modelo já tá com uma cara ótima e estamos próximos do fim! Porém, agora eu recomendo que você feche tanto o Meshing quanto a nuvem de pontos da visualização 3D porque elas consomem memória. Pra isso, é só clicar no x que tem do lado, ali perto de onde liga e desliga a visualização.
Mesh Filtering
Este módulo vai dar uma talento no nosso modelo, remover umas inconsistências e dar uma alisada. A documentação diz:
Este módulo aplica uma filtragem Laplaciana para remover defeitos locais da rede.
É isso, basta executar. Vai demorar uns 15 segundos. Você pode visualizar o resultado dando um clique duplo no módulo. Caso não goste e prefira usar o modelo sem a filtragem, é só desconectar o módulo do texturing e ligar o meshing direto nele.
Texturing
Chegamos na última parte! Agora, o nosso modelo de gesso vai ficar parecendo um objeto de verdade! Como de costume, vamos dar uma olhada na documentação:
Este módulo computa a textura na rede (mesh).
Se a rede não tem um UV associado, ele automaticamente computa os mapas UV.
Para cada triângulo, ele usa a informação de visibilidade de cada vértice para recuperar os candidatos a textura. Ele seleciona as melhores câmeras baseado na resolução que cobre esse triângulo. Finalmente, ele faz a média dos valores dos pixels usando bandas múltiplas no domínio de freqüência. Muitas câmeras contribuem para as freqüências baixas e apenas as melhores contribuem para as altas.
Ou seja, o que ele vai fazer agora é uma projeção das imagens sobre o modelo através de uma convolução delas. Parece grego? Tudo bem, é complicado mesmo. A boa notícia é que é só rodar o módulo e vai levar uns 6 minutos.
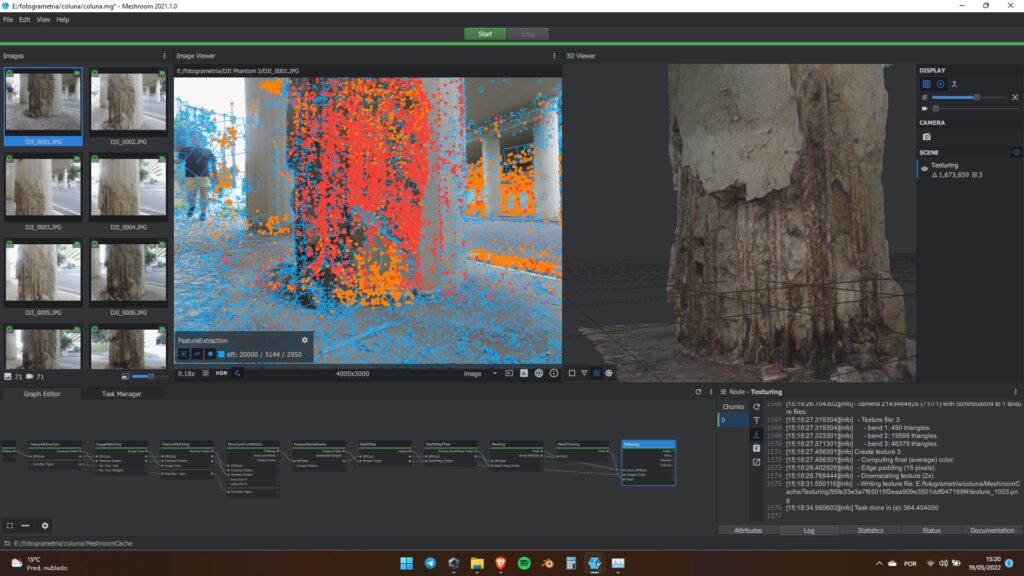
Pronto! A essa altura já devemos ter um belo modelo de coluna de concreto armado podre! Para visualizar o resultado, dê um clique duplo no módulo texturing que o Meshroom carrega ele no visualizador 3D. Deve ter ficado assim:
Como usar o modelo
Para conseguir usar o modelo fora do Meshroom, basta importar o arquivo .obj crado pelo texturing. Para isso, dê um clique com o direto sobre o módulo do texturing e clique em open folder. O arquivo estará nessa pasta. Agora é só abrir onde você quiser e usar. Note que o modelo que é ultra detalhado, inclusive com buracos e barras de ferro rompidas. O resultado é realmente incrivel.
E isso encerra o nosso tutorial!